The following graphic shows the results of an unsupervised, machine-learning clustering model:
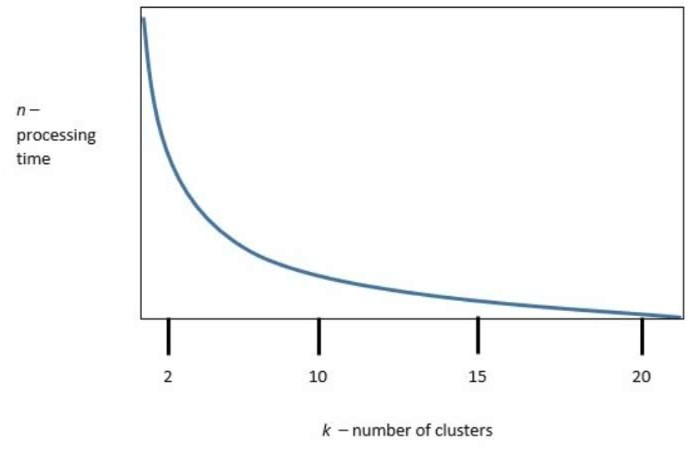
k is the number of clusters, and n is the processing time required to run the model. Which of the following is the best value of k to optimize both accuracy and processing requirements?
Show Answer
Hide Answer
Correct Answer:
B
The curve shows a steep drop in processing time up to about k = 10, after which gains in speed taper off. Choosing 10 clusters balances sufficient model complexity with reasonable computational cost.

