Get Full Access to CertNexus AIP-210 questions & answers in the format that suits you best
PDF Version
$40.00
$24.00
92 Actual Exam Questions
Compatible with all Devices
Printable Format
No Download Limits
90 Days Free Updates
Discount Offer (Bundle pack)
$80.00
$48.00
Discount Offer
92 Actual Exam Questions
Both PDF & Online Practice Test
Free 90 Days Updates
No Download Limits
No Practice Limits
24/7 Customer Support
Online Practice Test
$30.00
$18.00
92 Actual Exam Questions
Actual Exam Environment
90 Days Free Updates
Browser Based Software
Compatibility:
Pass Your CertNexus AIP-210 Certification Exam Easily!
Looking for a hassle-free way to pass the CertNexus Certified Artificial Intelligence Practitioner Exam? DumpsProvider provides the most reliable Dumps Questions and Answers, designed by CertNexus certified experts to help you succeed in record time. Available in both PDF and Online Practice Test formats, our study materials cover every major exam topic, making it possible for you to pass potentially within just one day!
DumpsProvider is a leading provider of high-quality exam dumps, trusted by professionals worldwide. Our CertNexus AIP-210 exam questions give you the knowledge and confidence needed to succeed on the first attempt.
Train with our CertNexus AIP-210 exam practice tests, which simulate the actual exam environment. This real-test experience helps you get familiar with the format and timing of the exam, ensuring you're 100% prepared for exam day.
Your success is our commitment! That's why DumpsProvider offers a 100% money-back guarantee. If you don’t pass the CertNexus AIP-210 exam, we’ll refund your payment within 24 hours no questions asked.
Why Choose DumpsProvider for Your CertNexus AIP-210 Exam Prep?
Verified & Up-to-Date Materials: Our CertNexus experts carefully craft every question to match the latest CertNexus exam topics.
Free 90-Day Updates: Stay ahead with free updates for three months to keep your questions & answers up to date.
24/7 Customer Support: Get instant help via live chat or email whenever you have questions about our CertNexus AIP-210 exam dumps.
Don’t waste time with unreliable exam prep resources. Get started with DumpsProvider’s CertNexus AIP-210 exam dumps today and achieve your certification effortlessly!
Free CertNexus AIP-210 Exam Actual Questions
Question No. 1
You have a dataset with thousands of features, all of which are categorical. Using these features as predictors, you are tasked with creating a prediction model to accurately predict the value of a continuous dependent variable. Which of the following would be appropriate algorithms to use? (Select two.)
Lasso regression and ridge regression are both types of linear regression models that can handle high-dimensional and categorical data. They use regularization techniques to reduce the complexity of the model and avoid overfitting. Lasso regression uses L1 regularization, which adds a penalty term proportional to the absolute value of the coefficients to the loss function. This can shrink some coefficients to zero and perform feature selection. Ridge regression uses L2 regularization, which adds a penalty term proportional to the square of the coefficients to the loss function. This can shrink all coefficients towards zero and reduce multicollinearity. Reference: [Lasso (statistics) - Wikipedia], [Ridge regression - Wikipedia]
Question No. 2
Word Embedding describes a task in natural language processing (NLP) where:
Word embedding is a task in natural language processing (NLP) where words are converted into numerical vectors that represent their meaning, usage, or context. Word embedding can help reduce the dimensionality and sparsity of text data, as well as enable various operations and comparisons among words based on their vector representations. Some of the common methods for word embedding are:
One-hot encoding: One-hot encoding is a method that assigns a unique binary vector to each word in a vocabulary. The vector has only one element with a value of 1 (the hot bit) and the rest with a value of 0. One-hot encoding can create distinct and orthogonal vectors for each word, but it does not capture any semantic or syntactic information about words.
Word2vec: Word2vec is a method that learns a dense and continuous vector representation for each word based on its context in a large corpus of text. Word2vec can capture the semantic and syntactic similarity and relationships among words, such as synonyms, antonyms, analogies, or associations.
GloVe: GloVe (Global Vectors for Word Representation) is a method that combines the advantages of count-based methods (such as TF-IDF) and predictive methods (such as Word2vec) to create word vectors. GloVe can leverage both global and local information from a large corpus of text to capture the co-occurrence patterns and probabilities of words.
Question No. 3
A big data architect needs to be cautious about personally identifiable information (PII) that may be captured with their new IoT system. What is the final stage of the Data Management Life Cycle, which the architect must complete in order to implement data privacy and security appropriately?
The final stage of the data management life cycle is data destruction, which is the process of securely deleting or erasing data that is no longer needed or relevant for the organization. Data destruction ensures that data is disposed of in compliance with any legal or regulatory requirements, as well as any internal policies or standards. Data destruction also protects the organization from potential data breaches, leaks, or thefts that could compromise its privacy and security. Data destruction can be performed using various methods, such as overwriting, degaussing, shredding, or incinerating
Question No. 4
A company is developing a merchandise sales application The product team uses training data to teach the AI model predicting sales, and discovers emergent bias. What caused the biased results?
Emergent bias is a type of bias that arises when an AI model encounters new or different data or scenarios that were not present or accounted for during its training or development. Emergent bias can cause the model to make inaccurate or unfair predictions or decisions, as it may not be able to generalize well to new situations or adapt to changing conditions. One possible cause of emergent bias is seasonality, which means that some variables or patterns in the data may vary depending on the time of year. For example, if an AI model for merchandise sales prediction was trained in winter and applied in summer, it may produce biased results due to differences in customer behavior, demand, or preferences.
Question No. 5
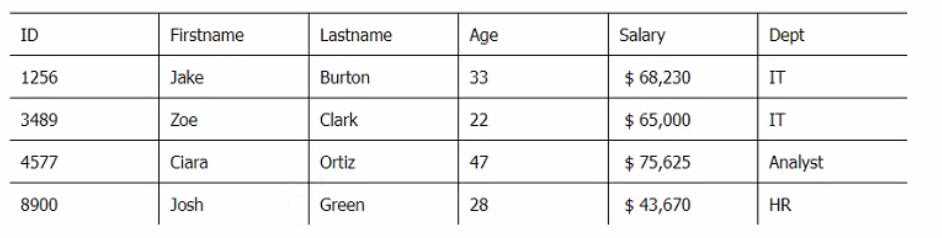
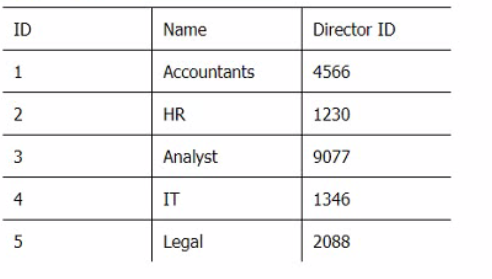
Below are three tables: Employees, Departments, and Directors.
Employee_Table
Department_Table
Director_Table
ID
Firstname
Lastname
Age
Salary
DeptJD
4566
Joey
Morin
62
$ 122,000
1
1230
Sam
Clarck
43
$ 95,670
2
9077
Lola
Russell
54
$ 165,700
3
1346
Lily
Cotton
46
$ 156,000
4
2088
Beckett
Good
52
$ 165,000
5
Which SQL query provides the Directors' Firstname, Lastname, the name of their departments, and the average employee's salary?
This SQL query provides the Directors' Firstname, Lastname, the name of their departments, and the average employee's salary by joining the three tables using the appropriate join types and conditions. The RIGHT JOIN between Employee_Table and Department_Table ensures that all departments are included in the result, even if they have no employees. The INNER JOIN between Department_Table and Directorjable ensures that only departments with directors are included in the result. The GROUP BY clause groups the result by the directors' names and departments' names, and calculates the average salary for each group using the AVG function. Reference: SQL Joins - W3Schools, SQL GROUP BY Statement - W3Schools